Pinning down the lower quartile in a dataset isn’t just a statistical exercise; it’s a pivotal skill for anyone engaged in data analysis, research, or even business intelligence. The lower quartile, or Q1, represents the 25% mark of your data, offering a snapshot of where the lowest 25% of data points reside. Understanding and accurately calculating this metric is essential for gauging the spread and distribution of data, especially when comparing different sets. This article delves deep into the intricacies of calculating the lower quartile, ensuring you grasp its importance and can execute it confidently.
Key Insights
- Q1 provides a measure of the first 25% of your data, which is critical for understanding data distribution.
- The calculation requires understanding of data ranking and quartile positioning.
- Utilize Q1 for identifying outliers and informing data-driven decisions.
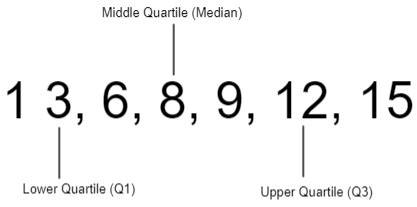
Understanding the Lower Quartile Calculating the lower quartile involves a straightforward yet methodical process. Firstly, arrange your dataset in ascending order. This fundamental step ensures that each data point is easily identifiable, setting the stage for accurate quartile calculation. Once your data is ordered, identify the position of Q1. This is done using the formula: Q1 Position = (n + 1) / 4, where ‘n’ represents the total number of data points. This formula pinpoints the index of the data point that marks the 25% mark in your ordered dataset.
Practical Application of Lower Quartile Calculation In practical terms, the lower quartile isn’t just an abstract number; it serves as a critical benchmark in various analytical contexts. For instance, in educational settings, Q1 can help determine the performance level of the lowest quarter of students, aiding educators in identifying areas where support is most needed. Similarly, in finance, analyzing the lower quartile of stock returns can highlight the least performing 25% of investments, crucial for risk management and portfolio diversification strategies.
Incorporating Lower Quartile in Statistical Analysis The lower quartile plays a vital role in statistical analysis, especially in conjunction with the median and upper quartile to form a more comprehensive picture of data distribution. For example, in environmental studies, researchers might use Q1 alongside Q3 to assess the variability in pollution levels across different geographical areas. This approach not only provides a clearer understanding of pollution distribution but also supports policy-making for areas requiring more stringent environmental regulations.
FAQ Section
Why is the lower quartile important in data analysis?
The lower quartile is essential for understanding data distribution. It helps identify the spread and the range of the lowest 25% of your data, which is critical for decision-making and outlier detection.
How do I handle outliers when calculating the lower quartile?
Outliers can skew the lower quartile calculation. To address this, consider using the lower quartile along with other metrics like the interquartile range (IQR), which excludes outliers, or employ robust statistical methods that are less sensitive to extreme values.
Grasping the nuances of the lower quartile calculation and its application can transform the way you approach data analysis. By focusing on this essential statistical tool, you’ll gain deeper insights into your datasets, enabling more informed and effective decision-making across various domains.
