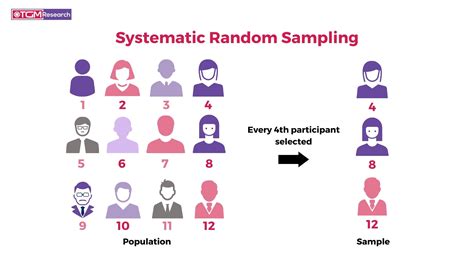
Researchers across disciplines seek reliable, unbiased methods for data collection. Systematic random sampling is a powerful, yet often misunderstood technique, pivotal for ensuring the integrity of research outcomes. This method, which integrates both randomness and systematic selection, helps ensure generalizability and minimizes biases that might skew results.
Key insights box:
Key Insights
- Systematic random sampling offers a balance between convenience and accuracy.
- Its implementation requires careful consideration of population size and sampling interval.
- Using this method leads to higher confidence in the research findings.
Systematic random sampling is grounded in selecting a starting point at random within the first sampling interval, and then picking every kth element thereafter. This technique’s strength lies in its ability to produce samples that reflect the population’s diversity while maintaining ease of execution. For instance, when surveying a large patient database, instead of selecting subjects purely by convenience or arbitrary choice, a researcher might choose a random starting point within the first 100 patients, then select every 20th patient following the first. This results in a representative subset that is both manageable and statistically sound.
The first analysis section emphasizes the practical relevance of systematic random sampling. This approach is invaluable in fields like public health, market research, and educational studies where exhaustive sampling is impractical. Its appeal comes from the clear and consistent methodology, making it easy for multiple researchers to replicate the sampling process exactly. When a public health study aims to analyze health records of 10,000 patients, employing systematic random sampling ensures the researcher’s sample is neither over-concentrated in a subset of the population nor missing critical data variance. Furthermore, systematic random sampling’s transparent process minimizes potential biases that might arise in less structured sampling methods, ensuring robust and replicable results.
The second analysis section delves into a technical consideration essential for successful implementation: determining the sampling interval (k). The interval should be meticulously chosen to prevent periodicities that might introduce bias. For example, in a retail setting where sales are higher on weekends, choosing a sampling interval that coincides with the weekends could skew results to show higher weekend sales consistently. Therefore, calculating k requires a firm grasp of the population size and ensuring it’s not a multiple of any periodicities in the data. The interval must be sufficiently small to capture the population’s diversity while being large enough to avoid over-representation of any subgroup.
FAQ section:
How does systematic random sampling differ from simple random sampling?
In simple random sampling, every member of the population has an equal chance of being selected, often using methods like lottery draws. Systematic random sampling, however, involves selecting a starting point randomly and then choosing every kth member of the population, creating a sample that’s easier to manage and replicate.
When should systematic random sampling not be used?
This method is less suitable when there are known periodic patterns within the population that could align with the sampling interval (k). For example, in time series data where certain events repeat at regular intervals, the systematic approach may over-represent or under-represent certain parts of the data.
Systematic random sampling remains a robust, flexible method within the researcher’s toolkit. It strikes a balance between thoroughness and practicality, producing reliable samples when used appropriately. Its thoughtful application in research helps ensure that findings are credible, unbiased, and truly reflective of the population being studied.